使用scrapy爬取动态漫画站

前段时间特别迷港漫,尤其牛佬的作品个人很喜欢。
奈何是个动态站点,图片地址都用 js 加密过,记录下爬取过程。
爬虫部分代码解析
1.1:章节获取
查看网站源代码,找不到章节名称关键字,F12 分析,确定章节内容为 ajax 提交完成。
交互采用 post 方式进行,scrapy 中可使用 FormRequest 完成提交动作。
Post 过程中 header 必须存在三个值,需自定义,代码如下:
|
1 2 3 4 5 6 7 8 9 |
headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36', 'Content-Type':'application/x-www-form-urlencoded; charset=UTF-8', 'X-Requested-With':'XMLHttpRequest' } def start_requests(self): url = 'https://www.xxxxxx.com/comicinfo-ajaxgetchapter.html' # FormRequest 是Scrapy发送POST请求的方法 yield scrapy.FormRequest(url = url, headers = self.headers, formdata = {'cartoon_id' : 'xxxxx', 'order_by' : '1', 'chapter_type' : '1'}, callback = self.parse) |
1.2:章节解析
返回内容为标准的 json 值,采用 json.loads 转换为 dict。(开头需 import json)
用 for 循环放入到 scrapy 的 item 中,此时得到章节所有详细页面地址,用 request 继续深入访问。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
def parse(self, response): ''' 解析漫画章节页面ajax ''' print("Start......") # 开始获取内容 chapter = json.loads(response.body) # 保存章节链接和名字len(chapter['msg']) for i in range(int(len(chapter['msg']))): item = GetcomicsItem() item['link_url'] = 'https://www.xxxxxx.com/series-xxxxxx-' + str(chapter['msg'][i]['system']['chapter_id']) +'-1-xxxx' item['chapter_name'] = chapter['msg'][i]['system']['title'] yield scrapy.Request(url = item['link_url'], meta={'item':item}, callback = self.parsepage) |
1.3:图片源地址获取
此时出现本次爬取最大难点,进入章节第一页后,固然无法通过右键获取到图片地址,F12 发现仍然为动态提交表单后获得,表单内容中有个 key 值不知从何而来。
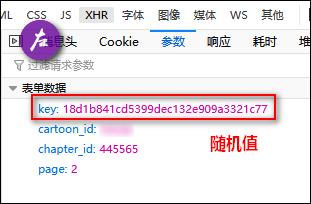
求助 @喵喵 后得知 key 是每次 get 请求页面时,随页面返回,此为随机值,故直接用正则找关键字截取字符串(开头需 import re),得到 key 后仍然使用 scrapy.FormRequest 完成表单提交。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
def parsepage(self, response): ''' 循环POST, 需要先get到页面的key后再POST出去得到图片地址 ''' # 接收传递的item item = response.meta['item'] # 需重新定义link_url的值, 循环页面必须, 否则link_url不更新 item = GetcomicsItem(link_url = response.url,chapter_name = item['chapter_name']) # 获取post需要的key等数据 # 在这里也有机会出现无法得到KEY的情况 (页面未返回) key = re.findall('KEY = "(.*?)"',response.text)[0] chapterid = re.findall('CHAPTER_ID = "(.*?)"',response.text)[0] totalpage = re.findall('TOTAL_PAGE = "(.*?)"',response.text)[0] item['chapter_totalpage'] = totalpage nowpage = re.findall('PAGE = "(.*?)"',response.text)[1] # 发送post请求图片地址 yield scrapy.FormRequest( url = 'https://www.xxxxxx.com/comicseries/getpictrue.html', headers = self.headers, meta = {'item':item}, formdata = {'key' : key, 'cartoon_id' : 'xxxxx', 'chapter_id' : chapterid, 'page' : nowpage}, callback = self.parsepic ) |
1.4:图片地址解密
返回是 eval 开头的加密 js,python 中使用 PyExecJS 库即可,解密后得到真实地址,放入 item,再返回丢给 pipelines 开始下载。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
def parsepic(self, response): ''' 破解eval方式的加密得到真实图片地址, 然后再循环GET章节页面(和总页面相等停止循环) ''' # 接收传递的item item = response.meta['item'] # 解析获取到的加密js picadd = response.text # 可能post回来图片地址是空值 picjs = execjs.compile(""" function decode(code) { code2 = code.replace(/^eval/, ''); return eval(code2); }""") trueadd = picjs.call("decode",picadd) additems = trueadd.split(';') #通过一番转换, 得到最终地址, 每页有两张图片, 只需要当前即可 realpicadd = additems[1][13:-1] if(realpicadd == ''): print("空值了!!!") print(item['link_url']) else: item['img_url'] = realpicadd #返回item开始下载图片 yield item |
1.5:循环 POST 分页
搞定第一页,还得继续循环后面的分页,回调函数 parsepage,需重新定义 item 值,不然 link_url 传值会有问题。
|
1 2 3 4 5 6 7 8 |
#处理后续页面的link_url front_link = 'https://www.xxxxxx.com/series-' + item['link_url'].split('/')[-1].split('-')[1] + '-' + item['link_url'].split('/')[-1].split('-')[2] + '-' back_link = item['link_url'].split('/')[-1].split('-')[4] #继续循环不要停(load 分页) #继续开始页码遍历(按照得到的totalpage计算) for each_link in range(2,int(item['chapter_totalpage'])+1): item['link_url'] = front_link + str(each_link) + '-' + back_link yield scrapy.Request(url=item['link_url'], meta={'item':item}, callback=self.parsepage) |
最后的成果
害怕源站被爬坏,代码内用 xxxxx 替代部分内容,这次的爬虫真心学习到不少东西,也是博主第一次使用 scrapy 框架完成的首个爬虫,虽然网上一堆教程,但都主要针对静态网站,这样的动态交互爬取把我折磨了好几个晚上。
上个单章爬取成功的图:
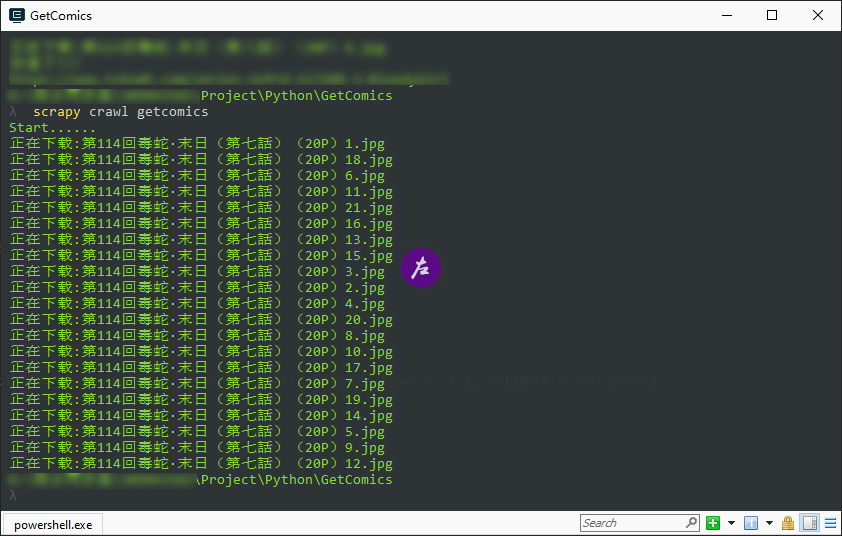
为什么代码没有完全分享出来,也是因为存在较大 bug,这样来回动态多线程交互的过程中偶尔会出现空值,空闲时间再研究解决(有个想法是检测为空后再重复 get 和 post 一次)。
感谢
最后特别感谢 @喵喵,几次卡壳的时候都是他给了我继续前行探索的动力。
此次爬虫也是对 Getpics 脚本的一次升华,年初立下用 python 写出一个实例的 flag 算是做得不错,感谢自己的坚持。
11 月试产要来了,得花大部分工作时间重新编写测试脚本,到时遇到有意思的再到博客记录吧。
-End-




2019年11月03日 21:10 沙发
分析到位~nice!
2019年11月03日 21:19
@点滴记录 你的评论才快~ 厉害!
2019年11月04日 10:37 板凳
2019年11月05日 19:04
@夏天烤洋芋 爬漫画是基本,空了哪天去爬个套图站,然后做个卖图包的微信群,也~~ 产业链出来了
爬漫画是基本,空了哪天去爬个套图站,然后做个卖图包的微信群,也~~ 产业链出来了
2019年11月04日 18:45 地板
这个爬虫威力好大,如入无人之境
2019年11月05日 14:18 4楼
就喜欢你们这些有技术的
2019年11月05日 19:09
@从良未遂 都是入门级入门级

2019年11月05日 16:02 5楼
爬漫画,这个我喜欢!
2019年11月05日 19:10
@云中君 不,你喜欢我下次发爬美女才对
2019年11月11日 16:10 6楼
2019年11月16日 10:16 7楼
真羡慕,还在学习中