用python写的漫画下载工具getpics

近期自学 Python 中,正好发现一部不错的漫画想下载到本地保存。
代码写得很基础很简单,枉我还是科班毕业,学习新语言费了很大劲。
这个工具暂时不是爬虫,后期如有时间会陆续完善成强大的漫画下载器。
分析过程
起因:去年年末开始,腾讯漫画平台很多作品突然就完结或消失,很多好的漫画已无法在线阅读,幸有漫友推荐发现某网站,为防资源丢失,于是想保存下来,话说总不能一张张另存为吧,所以有了这次用 Python 练手的机会。
漫画《Bloody Girl》,用浏览器开发者工具分析如下图
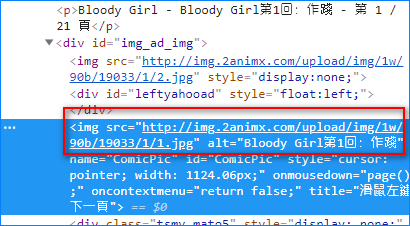
网站没有使用图片 CDN,也没使用动态网页,地址是明文并且一眼就看出规律。
upload/img/1w/90b/19033/1/1.jpg
upload/img/1w/90b/19033/1/2.jpg
然后第二章
upload/img/1w/90b/19033/2/1.jpg
upload/img/1w/90b/19033/2/2.jpg
这么规范的地址连爬虫都不需要,直接下载就好,简单画下软件逻辑。
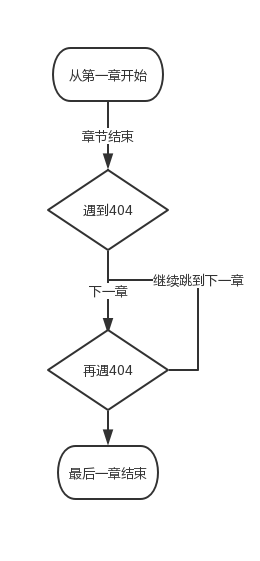
判断只做了 404,下载到章节最后一张图片无效后就进入到下一章,因为此网站有些章节重复且无效,所以再次判断如果 404 再进入下一章直到结束。
代码分享
GitHub 地址:https://github.com/bwskyer/Getpics
说明下,第一次用 Python 写工具,代码不是很精简,后面再优化。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 |
#coding=utf-8 import os #建立本地目录使用 import time #写了一个1秒延时 a = 1 #起始章节 b = 1 #起始页面 c = 271 #定义总章节,当大于此章节循环跳出 errorcode = 200 #先定义正常代码 #定义下载方法方便调用 def picdownld(): os.makedirs(folder, exist_ok=True) from urllib.request import urlretrieve urlretrieve(IMAGE_URL, picname) while b < 100: #定义下载地址 IMAGE_URL_HEAD = "http://img.2animx.com/upload/img/1w/90b/19033/" IMAGE_URL_MID = str(a) PIC_URL_END = "/"+ str(b) +".jpg" IMAGE_URL = IMAGE_URL_HEAD + IMAGE_URL_MID + PIC_URL_END #定义本地电脑保存目录 folder = './pics/' + str(a) + '/' pictitle = str(b) + '.jpg' picname = folder + pictitle #判断下载地址是否有效 from urllib import request from urllib import error req = request.Request(IMAGE_URL) try: responese = request.urlopen(req) except error.HTTPError as e: errorcode = e.code if errorcode == 404: #如果地址无效跳下一章节,有效就进行下载 errorcode = 200 #只会返回错误的情况,所以必须重置返回值 a = a + 1 if a > c: break b = 1 IMAGE_URL_MID = str(a) PIC_URL_END = "/"+ str(b) +".jpg" IMAGE_URL = IMAGE_URL_HEAD + IMAGE_URL_MID + PIC_URL_END folder = './pics/' + str(a) + '/' pictitle = str(b) + '.jpg' picname = folder + pictitle req = request.Request(IMAGE_URL) try: responese = request.urlopen(req) except error.HTTPError as e: errorcode = e.code if errorcode == 404: #如果再次404跳下一章节继续判断 errorcode = 200 #只会返回错误的情况,所以必须重置返回值 a = a + 1 continue picdownld() #调用下载方法 b = b + 1 #图片+1 print(IMAGE_URL + '下载完成') time.sleep(1) print('All done,一切安好') |
使用说明和截图
这个工具只供个人学习使用,当然如果你也喜欢漫画,请随意。
使用方法仔细看注释,不单独废话,分享下成功的截图。
漫画会下载到当前运行目录下的 pics 中并按照有效章节建立次目录。
下载
使用代码前先下载 Python,download from 百度网盘,提取码:yuh4
新年立下的 flag 完成一个,虽然只是很简单的工具,但是是不错的开始。
-End-




2019年02月22日 16:26 沙发
2019年02月22日 16:29
@夏天烤洋芋 你动作真快,难道阅读器随时开着的?
2019年02月22日 16:30 板凳
2019年02月22日 16:32
@夏天烤洋芋 可是我才更新呀,这么巧刚更新你就看到了,我还以为阅读器还有手机微信提示呢
2019年02月22日 19:34
@夏天烤洋芋 你博客有毒呀,评论都没办法提交,是成功还是卡住了一点提示没有,真的可以换服务器了
2019年05月09日 00:21
@Sam.Z 我刚才也遇见这个问题了,说我已经发送过重复评论了,不过我重新编写评论内容后,发送出去了。
2019年02月22日 22:12 地板
向大佬学习,最近也在看Python,收下你的源码了!
2019年02月23日 10:25
@xzymoe 小moe谦虚了,我才刚刚学习,都是很简单的东西,向你学习~
2019年02月23日 07:55 4楼
高深的代码看着就蒙圈,只有傻瓜教程适合我
2019年02月23日 10:28
@响石潭 谦虚了,如果有什么需要简单编程的,可以找我,不超过1000行的代码我就当练练手
2019年02月23日 11:35 5楼
2019年02月24日 04:50
@bosir 按照现在的使用情况,确实如此,主要是这门语言真的很方便
2019年02月24日 10:16 6楼
技术大牛
2019年02月24日 10:26
@nice 我是技术渣,都是些基础东西,刚才没登陆回复的,重新来一次
2019年02月25日 12:32 7楼
小工具,大作用。许多工具软件也是从当初的一个小技能开始开发的。加油,期待看到更多的作品。
2019年02月25日 13:53
@maqingxi 感谢鼓励,下一步我准备用Python写一个侦测微信好友拉黑删除的工具,好友要清理下,太多没用的了。
2019年02月25日 21:19 8楼
现在貌似很流行Python
2019年02月26日 09:28
@鸟叔 确实是,所以也学习一下玩玩,感觉确实很方便,库很强大
2019年02月27日 00:38 9楼
py大佬啊
2019年02月27日 10:07
@清秋的沙海 你才是大佬,我初学者,大学的时候学的C#,好多年没用了
2019年02月27日 10:41
@Sam.Z 我大学也是学C#的
2019年02月27日 11:11
@清秋的沙海 大致能猜到,已访问过贵博客,订阅了,向你学习
2019年03月09日 15:55 10楼
大佬
2019年03月11日 13:57
@明月清风 小工具,如果哪天你需要类似的小工具我可以帮你写
2019年05月09日 00:22
@Sam.Z 我上个月,刚找个技术写了一套imessages群发推送系统,貌似他就是用Python写的,看样子这个语言真的很强大,哈哈,博主接私单吗?我们找机会聊聊。

2019年05月09日 00:26
@耳朵的主人 哈哈哈,个人业余爱好而已,不接单,大学就是学的编程,所以偶尔喜欢小玩一下,很少写了。
2019年12月25日 23:19 11楼
不超过1000行当练手,请问是真的吗?
那个,我正好有一事想请教。
是做一个输入书名自动检索豆瓣上的ISBN、作者、出版社信息,然后可以和书名一起输出excel格式,或者文本PDF。
主要是用来给图书馆荐书用。
2019年12月25日 23:37
@poto 不用重复评论发,不超过1000的代码几乎都是练习使用,你写的需求已经算是爬豆瓣的数据了,书名有可能有重复,所以还要判断,至于存到excel和PDF这个有现成的模块。